728x90
반응형
SMALL
데이터레이크는 오브젝트, 블럽(Blob), 파일 등의데이터를 원시형상 그대로 저장하는 시스템 혹은 저장소를 말한다. 데이터레이크는 일반적으로 소스 시스템 데이터, 센서데이터, 소셜데이터 등의 원시데이터 복제본이나, 보고서, 시각화, 고급분석 및 기계학습과 같은 작업을 목적으로 변환된 데이터 등을 저장하기 위한 단일의 저장소로서 아래와 같은 데이터 유형을 포함할 수 있다.
정형데이터 - 관계형데이터베이스(RDB)
반정형데이터 - CSV, Logs, XML, JSON
비정형데이터 - 이메일, 문서, PDF
바이너리데이터 - 이미지, 오디오, 비디오
(원문출처 : https://en.wikipedia.org/wiki/Data_lake)
데이터레이크의 개념을 이해하기 전에 데이터웨어하우스에 대해서 먼저 이해할 필요가 있다. 오래전부터 기업들은 주요 비즈니스에서 생성된 데이터를 분석함으로서, 비즈니스 향상을 위한 인사이트를 얻고, 임원들의 의사결정을 돕기위한 정보를 제공해왔고, 이러한 욕구가 다양한 업무 부서로 확산됨에 따라 수집 및 분석의 범위가 광범위해졌다.
한마디로 분석을 위한 데이터 소스(시스템)도 많아지고, 분석을 위한 도구(시스템)도 많아지면서, 각각의 소스와 분석 시스템을 연결하는 인터페이스는 기하급수적으로 늘어나게 되었다. 이는 엄청난 비효율을 초래하게 되었는데 이를 개선하는 방법이 데이터웨어하우스 이다.

이는 물류시스템과 비교하여 이해해볼 수 있겠다. 출발지와 목적지를 각각의 방법으로 연결하는 대신, 주요 거점에 물류기지를 운용함으로서 물류 효율을 획기적으로 개선하는 것과 같은 개념이다.
그러나 데이터웨어하우스는 관계형 데이터베이스와 같은 구조화된 데이터를 위한 솔루션이고, 비정형 데이터를 포함한 다양한 형식과 방대한 양의, 이른바 빅데이터를 통해 인사이트를 얻고자 하는 조직들에게는 다른 접근방법이 필요했다.
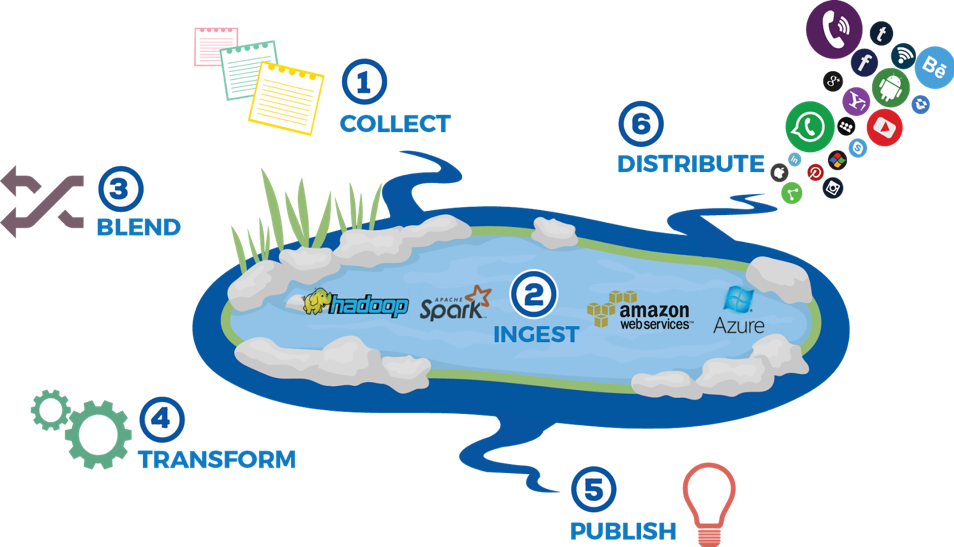
이를 위한 개념이 데이터 레이크이다. 조직 내의 다양한 소스로부터 나오는 모든 데이터를 원시형식 그대로 한 곳에 저장하는 '데이터 저수지'의 개념으로 이해하면 되겠다.
다음 포스팅에서는 데이터 레이크를 구현하기 위한 다양한 접근방법에 대해 알아보고자 한다.
728x90
반응형
LIST
'정보기술 > 데이터' 카테고리의 다른 글
| AI 기반 워크플로우 자동화 솔루션 도입, 어디까지 준비해야 하나? (0) | 2025.02.24 |
|---|